Our platform can handle all of your delinquency needs from one day past due through charge off.
Best-in-class results
Recover faster with HeartBeat, our patented machine learning platform that automatically improves and optimizes engagement over time.
Better for consumers
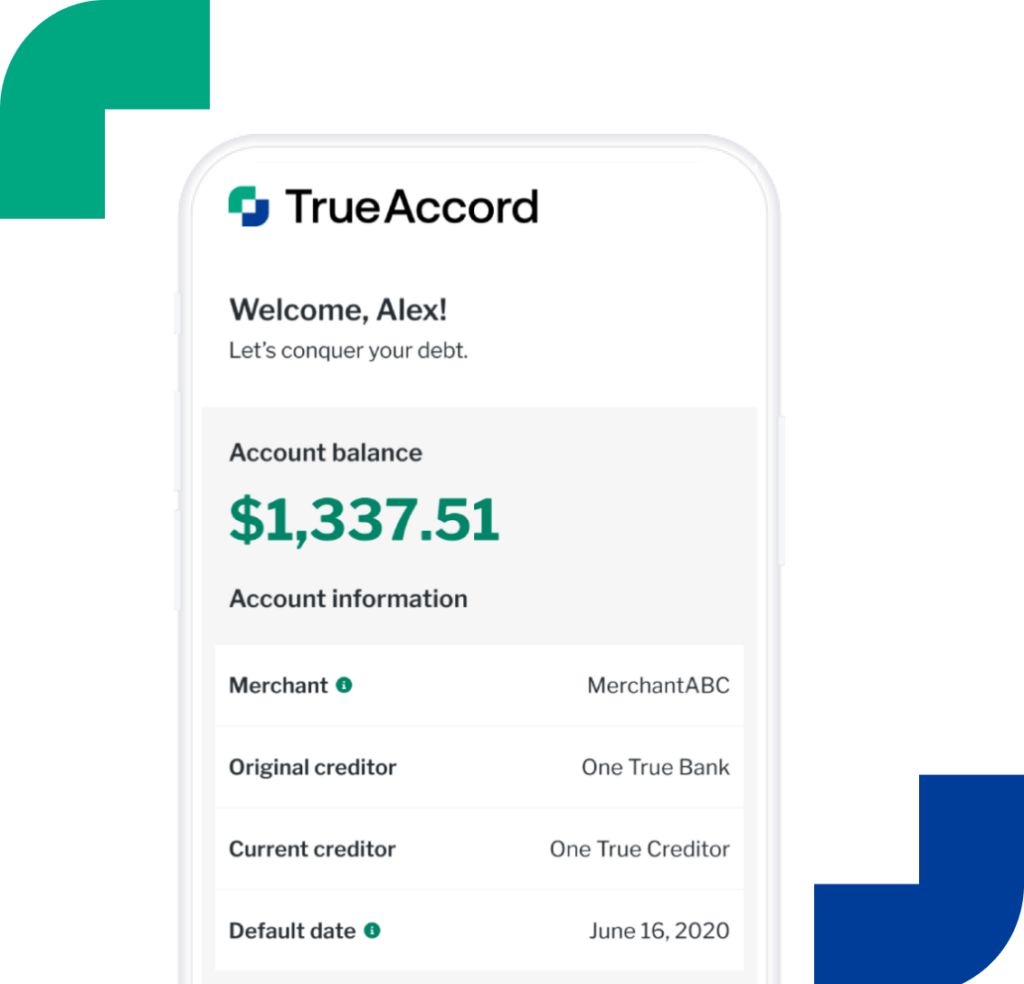
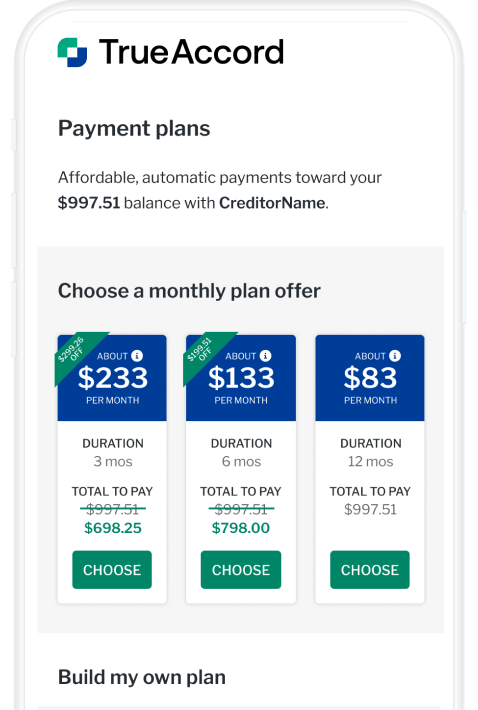
Give people the power to settle their debts with a flexible, self-serve digital experience.
Scalability
Delinquency infrastructure that can scale efficiently to any collections or recover volume.
End-to-end personalization
Reach consumers with the right message, on the right channel, at the right time.
See how HeartBeat delivers world class results.
Play Video
OUR SOLUTIONS
TrueAccord
Late Stage Collections
TrueAccord offers third-party collection services for better relationships and faster recoveries. Achieve higher liquidation through engagement, commitment, and resolution. All made possible through machine learning and a digital user experience.
We’re leaders in our field and work with trusted industry organizations and regulators.
“We had a very positive experience. We started using them and the performance felt strong enough where we have never tested them against any other vendor.”
“Nobody comes close to touching TrueAccord on net liquidation for end of the funnel debt.”
“TrueAccord is ~40-60% better than traditional agencies.”
Previous
Next
Featured E-Book / Report
Why Evolve from Outbound Calling to Omnichannel Engagement?
In this data-driven eBook, compare traditional outbound calling methods versus a digital-first omnichannel approach for debt collection.